Welcome back, my aspiring hackers!
Before embarking upon the study of web application hacking, you need to be familiar with the technologies being used by web apps. To hack the web applications, we need at least a cursory understanding of the multitude of technologies being implemented into modern web applications. To that end, I will try to provide you the basics on the key web technologies that may be exploited in taking control of a web application.

HTTP Protocol
The HyperText Transfer Protocol or HTTP is the granddaddy of web technologies. It is the core communication protocol of the web and all web applications use it. It’s a simple protocol originally designed to retrieve static web pages. Over the years, it has been updated and extended to offer support to complex applications that are common today.
HTTP uses a message based model where the client sends a request and the server responds with a response. It is connection-less, but uses TCP as its transport mechanism.
HTTP Requests
All HTTP messages contain the same basic elements;
1. One or more headers
2. Then a blank line
3. An optional Message Body
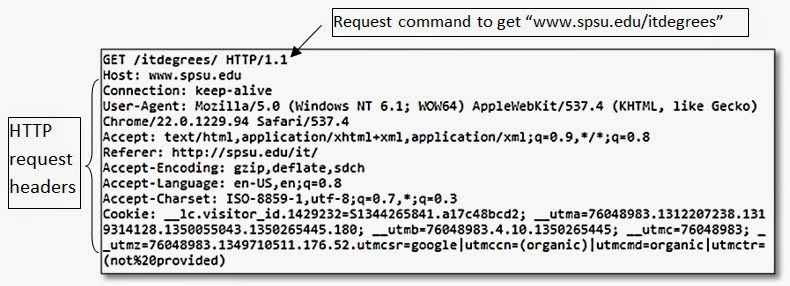
The first line of the HTTP requests has three elements, separated by spaces
1. A verb (action word) indicating the HTTP method (see methods below). Among these, the most common is GET. The GET method retrieves a resource from the web server
2. The requested URL
3. The HTTP version used
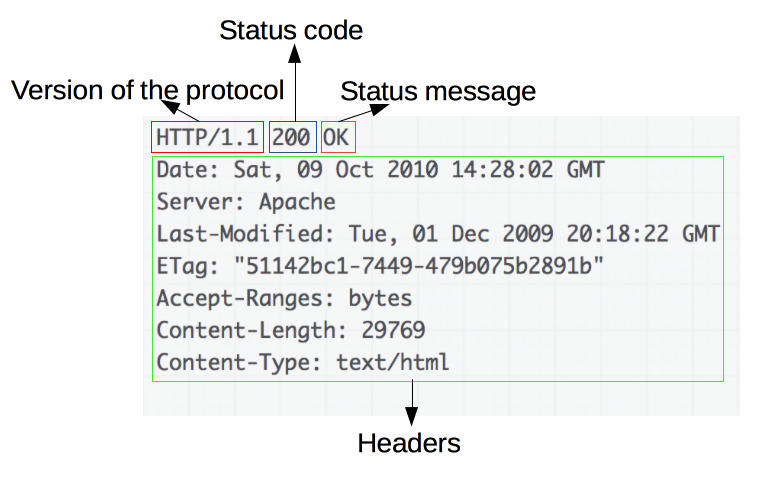
HTTP Responses
The typical HTTP response consists of three items;
1. The HTTP version
2. The numeric status code (see status codes below).
3. The text describing the status response.
HTTP Methods
When we attack web applications, we are most commonly making a request to the web server. This means that our methods will likely be either a POST or GET. There are subtle differences between these two requests.
The GET method is built to retrieve resources.
The POST method is built to perform actions.
Other Methods
HEAD functions similar to a GET request, but no message body is returned
TRACE is used for diagnostic purposes
OPTIONS asks the server to report HTTP methods are available
PUT attempts to upload a resource to the server which is contained in the body
URL’s
The uniform resource locator (URL) is a unique ID for every web resource for which a resource can be retrieved. This is the all familiar URL that we use every day to access information on the web.
The basic syntax of the URL is:
protocol://hostname[:port]/ [/path/] file [?param=value]
The port number is optional and only necessary if the port is different from the default port used by the protocol specified in the first field (http=80, https=443, ftp=21, etc).

HTTP Headers
There are numerous types of HEADERS in HTTP. Some can be used for both requests and responses and others are specific to the message types.
These are some of the common header types;
General Headers
* Connection – tells the other end whether connection should close after HTTP transmission
* Content-Encoding – specifies the type of encoding
* Content-Length – specifies the content length
* Content-Type – specifies the content type
* Transfer-Encoding – specifies the encoding on the message body
Request Headers
* Accept – specifies to the server what type of content it will accept
* Accept-Encoding – specifies to the server what type of message encoding it will accept
* Authorization – submits credentials
* Cookie – submits cookies to server
* Host – specifies host name
* If-Modified-Since – specifies WHEN browser last received the resource. If not modified, the server instructs the client to use cached copy
* If-None-Match – specifies entity tag
* Origin – specifies the domain where the request originated
* Referer – specifies the URL of the requestor
* User-Agent – specifies the browser that generated the request
Response Headers
* Access-Control-Allow-Origin – specifies whether the resource can be retrieved via cross-domain
* Cache-Control – passes caching directive to the browse
* Etag – specifies an entity tag (notifies the server of the version in cache)
* Expires – specifies how long the contents of the message body are valid
* Location – used in redirect responses (3xx)
* Pragma – passes caching directives to browser
* Server – specifies the web server software
* Set-Cookie – issues cookies
* WWW-Authenticate – provides details of type of authentication supported
* X-Frame-Options – whether and how response may be loaded within browser frame
Cookies
Cookies are critical part of HTTP. Cookies enable the server to send items of data to the client and the client stores this data and resubmits it to the server the next time a request is made to the server.
The server issues a cookie to the client using the SET-COOKIE response header.
SetCookie: Tracking=wdr66gyU34pli89
When the user makes a subsequent request to the server, the cookie is added to the header.
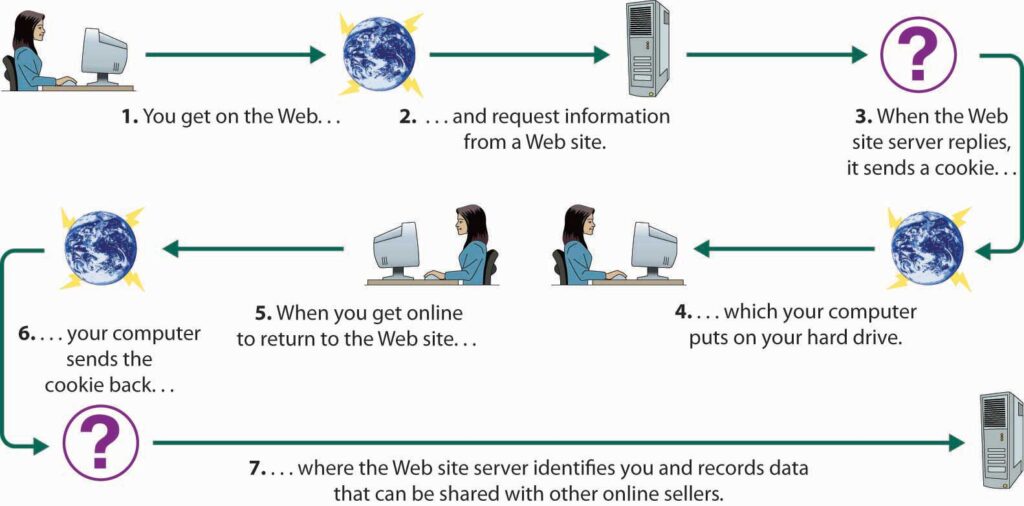
Cookies are used to identify the user to the server and other key information to the server. These cookies are usually a name/value pair and do not contain a space.
Status Codes
Every HTTP response must contain a status-code indicating the the result of the request. There are five groups of status codes based upon the first digit of the code.
* 1xx – Informational
* 2xx – Success
* 3xx – Redirect
* 4xx – Error
* 5xx – Server encountered an error
The status codes you are most likely to encounter are;
* 100 – Continue
* 200 – OK
* 201 – Created
* 301 – Moved Permanently
* 302 – Found
* 304 – Not Modified
* 400 – Bad Request
* 401 – Unauthorized
* 403 – Forbidden
* 404 – Not Found
* 405 – Method Not Allowed
* 413 – Request Entity Too Large
* 414 – Request URI Too Long
* 500 – Internal Server Error
* 503 – Service Unavailable
To see a complete list of all the response codes, see the list below.

Cookies are used to identify the user to the server and other key information to the server. These cookies are usually a name/value pair and do not contain a space.
Status Codes
Every HTTP response must contain a status-code indicating the the result of the request. There are five groups of status codes based upon the first digit of the code
* 1xx – Informational
* 2xx – Success
* 3xx – Redirect
* 4xx – Error
* 5xx – Server encountered an error
The status codes you are most likely to encounter are;
* 100 – Continue
* 200 – OK
* 201 – Created
* 301 – Moved Permanently
* 302 – Found
* 304 – Not Modified
* 400 – Bad Request
* 401 – Unauthorized
* 403 – Forbidden
* 404 – Not Found
* 405 – Method Not Allowed
* 413 – Request Entity Too Large
* 414 – Request URI Too Long
* 500 – Internal Server Error
* 503 – Service Unavailable
To see a complete list of all the response codes, see the list below.
HTTP Authentication
The HTTP protocol has its own mechanisms for authenticating users. These include;
Basic: sends user credentials as Base64-encoded string in request header
NTLM: challenge response mechanism
Digest: challenge response and uses MD5 check sums of a nonce with users credentials
In Web App Hacking, Web Technologies, Part 2, we will examine some of the web functionality technologies that that enable websites to deliver such rich, dynamic experiences to the modern websites such as AJAX, JSON, HTML5 and the content management systems that implement them.