Welcome back, my aspiring cyber warriors!
This next subject might seem a bit obscure to the uninitiated–but I promise– this lesson will benefit you significantly either as a hacker or system admin. This tutorial will cover what is usually referred to as a regular expressions, or regex for short.
Manipulating Text in Linux
Remember, nearly everything in Linux is a file, and for that matter, most are simple text files. Unlike Windows, with elaborate snap-ins and MMCs to configure an application or server, Linux simply has a text file for configuration. Change the text file, change the configuration. As a result, early pioneers in Linux developed some rather elaborate and elegant ways to manipulate text.
We’ve looked at a few simple ways to manipulate text already, such as grep and sed, but with regex we’ll have the capability to find much more complex text patterns.
For instance, what if we we’re looking for a line of code among millions of lines of code that began with an “s” containing only the letters “sugr” and the numbers 1-5 with a “bb” at the ending? Could we find it without having to go through millions of lines of code? Yes—with regex!
The Importance of Learning Regex
Regex is implemented throughout the information technology world. First developed in 1956 and adopted by Ken Thompson in the original UNIX, it has now found its way into Java, Ruby, PHP, Perl, Python, MySQL, Apache, .NET, and, of course, Linux.
Without understanding regex, you’re not only hamstrung in scripting any of these languages, but your ability to do more than simple search and replaces becomes very tedious. In addition, many of the rules written into Snort and other intrusion detection systems are written in regex.
As you can imagine, if searching for some malicious code, the ability to search and find sophisticated and complex text patterns is crucial.
How Regex Works in a Security Environment
In this tutorial, we’ll be using examples from the Snort ruleset to illuminate how regex works in a hacking/security environment.
Step 1: A Snort Rule
Of the many applications and scripting languages that use regular expressions, Snort is one. With its ability to detect just about any type of attack, Snort would be crippled without its regex capabilities. Let’s look at new rule that came out just few weeks ago to detect the Ransomware attacks that were seen across the world.
The Snort Rule for Detecting Ransomware Attacks
If you are not familiar with Snort rules, you may want to familiarize yourself by reading this tutorial in the Snort section of Hackers-Arise.
Our sample rule from the Snort community rule set.
alert tcp $HOME_NET any -> $EXTERNAL_NET $HTTP_PORTS (msg:”MALWARE-CNC Win.Ransomware.PRISM outbound connection attempt – Get lock screen”; flow:to_server,established; content:”GET”; http_method; content:”/page/index_htm_files2/”; nocase; fast_pattern:only;pcre:”/\x2f((xr)_a-z)|[0-9]{3,}\x2e(css|js|jpg|png|txt)$/U”;
http_uri; metadata:impact_flag red, policy balanced-ips drop, policy security-ips drop, ruleset community, service http reference:url,http://www.virustotal.com/en/file/417cb84f48d20120b92530c489e9c3ee9a9deab53fddc0dc153f1034d3c52c58/analysis/1377785686/; classtype:trojan-activity; sid:1000033; rev:3;)
End of Rule
Note the section that is in bold. This is the part of the rule that is utilizing pcre (Perl Compatible Regular Expressions) to detect the ransomware.
We’ll come back to this particular rule in a later tutorial, but for now, let’s look at a simple Snort rule using regular expressions. If you are unfamiliar with Snort rules, make sure to check out my previous guide on reading and writing Snort rules.
For our example, let’s use this following pseudo-rule:
alert tcp any any -> any 80 ( pcre:”/\/foo.php?id=[0-9]{1,10}/”;)
The first part of this rule should be familiar to us. It says “send an alert when a packet comes across the wire using the TCP protocol from any IP address from any port to any IP address to port 80”. It’s what comes after the header of this rule that is new and strange.
Our task now, is to figure out what this rule is looking for.
Step 2: Some Basic Syntax
Before we begin to attempt to decipher what that rule is looking for, let’s layout basic and simple regular expression syntax and rules.
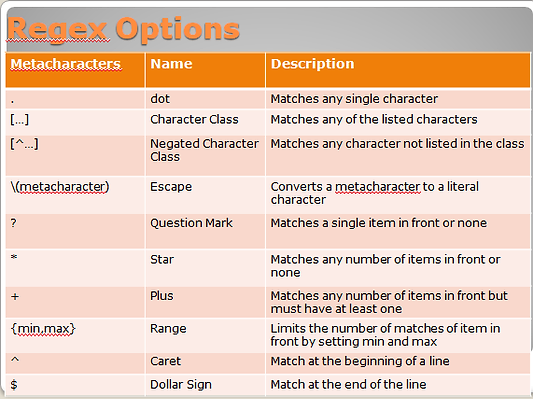
/ – Begins and ends a regular expression.
. – Matches any single character.
[…] – Matches a single character within the brackets.
[^…] – Matches everything except what is in-between the brackets (and after the ^).
[x-y] Matches every character or number in-between x & y (ex: [a-d]will match the letters a,b,c, or d and [2-7] will match the numbers 2,3,4,5,6, and 7. They are case sensitive by default, and can be combined however you like. For example, to match any alphanumeric character, you can use [A-Za-z0-9]).
^ – Matches the starting position of the string.
* – Matches the preceding element or group zero or more times.
$ – Matches the ending position of the string.
( ) – Defines an expression or group.
{n} – Matches the preceding character n times (ex: {5} would require the preceding character or group to match 5 times).
{m,n} – Matches the preceding element at least m times and not more than n times (ex: {2,4} would require the preceding character or group to appear 2-4 times in a row).
| – Matches the character or group either before OR after the |.
The following table summarizes some of the most important regex options.
In addition to the regex options, regex also has shortcuts. These are symbols that represent such things as word boundary or any digit or any alphanumeric, digit or underscore (the legitimate symbols in creating a file name).
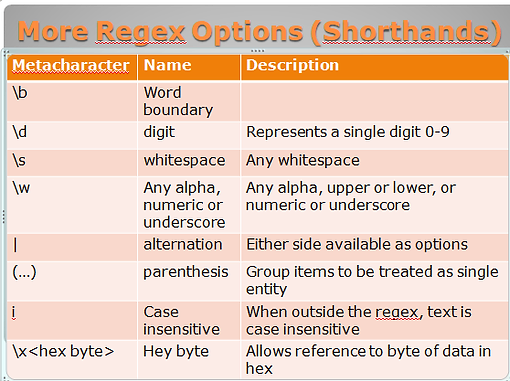
Step 3: Interpreting the Rule
The above tables summarize some of the very basic rules of regular expressions. Let’s try breaking down the regular expression built into the Snort rule above and try to determine what it is looking for.
pcre:”/\/foo.php?id=[0-9]{1,10}/”;
pcre: – This simply tells the Snort engine to start using Perl Compatible Regular Expressions on everything that follows.
” – Indicates the beginning of the content.
/ – Indicates the beginning of the subexpressions that the PCRE is looking for.
\ – This is an escape character—it says “don’t use the special meaning that the following character has in pcre,” but instead see it as literal character.
/foo.php?id= – This is simple text—the rule is looking for this set of characters.
[0-9] – The brackets here indicate look for any of the digits between 0-9.
{1,10} – The curly braces here say look for the previous digits between 1 and 10 times.
/ – End the expression we are searching for.
We could then interpret this rule to say in standard English, “look for (presumably a URL) that ends with “foo.php?id=” and then has a single digit between 0 and 9 [0-9] and that digit can be repeated between 1 and 10 times {1.10}.”
This rule would then catch packets that include the text patterns:
foo.php?id=1
foo.php?id=3
foo.php?id=33
foo.php?id=333333
But would pass packets with:
bar.php?id=1 bar instead of foo
foo.php?id= must have at least one digit
foo.php?id=A must have a digit not an alphabetic
foo.php?id=11111111111 can only have between 1 and 10 digits after the =
Summary
Regular Expressions or regex (pcre in Snort) are a powerful tool to find complex text patterns. Investing a small amount of time into becoming familiar with this simple language will save you many hours as a security engineer or hacker!